Review: Image-to-Image Translation and Applications
สวัสดีครับ เนื่องจากวันที่ 25 พฤศจิกายน ถึงวันที่ 27 พฤศจิกายน 2020 ทางLineได้จัดงาน Line Developer Day 2020 โดยงานนี้จะเป็นงาน conference ทางด้าน tech ที่เปิดให้ผู้ที่มีสนใจสามารถเข้าไปร่วมฟังได้ ภายในงานทั้ง3วันจะประกอบด้วยหลายหัวข้อที่น่าสนใจ เช่น AI/Data | Server Side LINE Platform | Security | Infrastructure | Mix Track | Casual Track ซึ่งแต่ละหัวข้อก็จะมีผู้เชี่ยวชาญด้านนั้นๆมาบรรยาย
โดยหัวข้อที่ผมรู้สึกสนใจและขอหยิบยกมาพูดจากงาน Line Developer Day 2020 ครั้งนี้ จะเป็นหัวข้อ Image-to-Image Translation and Applications ครับ เนื่องจากตัวผมนั้นมีความสนใจในเรื่องของcomputer visionเป็นทุนเดิมอยู่แล้ว
ก่อนอื่นที่เราจะไปเข้าเนื้อหาเรามาทำความรู้จักกันก่อนว่า Image-to-Image Translation คืออะไร?
Image-to-Image translations นั่นก็คือการที่เราเปลี่ยนรูปภาพประเภทหนึ่งให้ไปเป็นรูปภาพอีกประเภทหนึ่ง ยกตัวอย่างเช่น การเปลี่ยนรูปม้าไปเป็นม้าลาย หรือการเปลี่ยนสีเสื้อจากสีหนึ่งให้เป็นอีกสีหนึ่ง เป็นต้น
เมื่อเราได้รู้จักกับ Image-to-Image translations แล้ว เราก็มาเข้าถึงเรื่องของ Image-to-Image Translation and Applications ในงาน Line Developer Day 2020 กัน~~
Image-to-Image Translation and Applications ในงาน Line Developer Day 2020 จะพูดถึงวิวัฒนาการของ Generative Adversarial Networks หรือเรียกสั้นๆว่า GAN Model โดยตัวของ Image-to-Image เป็นหัวข้อที่น่าสนใจมากเกี่ยวกับเรื่องของ Computer Vision โดย session นี้ได้นำเสนอเกี่ยวกับกระบวนการของ Image-to-Image Translations ตัวล่าสุด และApplications ต่างๆ
อธิบายเรื่องของ Generative adversarial networks หรือ GAN Model คร่าวๆ คือ ตัวโมเดลจะมีการแบ่งเป็น 2 หน้าที่หลัก ๆ คือการสร้างรูปภาพ (Generative) และการเดารูปภาพว่าถูกหรือผิด (Discriminator)

โดยหัวข้อ Image-to-Image translations ก็จะมี
- pix2pix
- SPADE
- Unpaired Image-to-Image Translation
- Multi-Modal Image-to-Image Translation
- Limitation of prior work
- Multi-Domain Image-to-Image Translation Model : StarGANv2, COCO-FUNITD
- Applications 😺
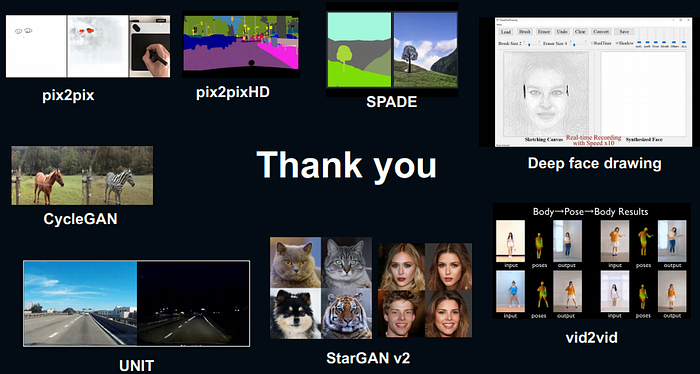
pix2pix

model อันแรกๆเรียกว่า pix2pix คือจะเป็นการทำงานระหว่าง 2 model คือ generator และ discriminator โดยหลักๆคือ discriminator จะเรียนรู้ว่ารูปภาพไหนเป็นภาพ real หรือ ภาพ fake ส่วนของ generator จะทำหน้าที่พยายามหลอก discriminator ว่าภาพที่สร้างขึ้นมาเป็นภาพจริง
SPADE

เป็นเหมือนการสร้างภาพใหม่จาก label map ในแนวแกน x และสามารถใส่ style ลงไปด้วยได้ในแนวแกน y เพื่อให้ model ของเราพยายามที่จะสร้างภาพโดยมีเรื่องของ styleมาเกี่ยวข้องด้วย
Unpaired Image-to-Image Translation
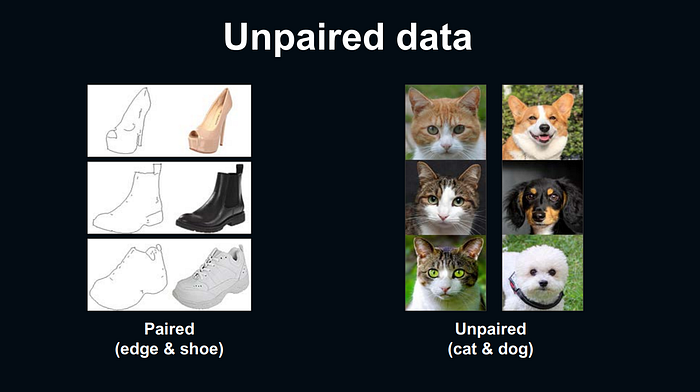
จากข้างบน ถ้าเราต้องการจะสร้างรูปอะไรขึ้นมา input กับ output จะต้องเหมือนกับ data ที่ train ไว้กับ model จะเป็นเรื่องยากมากที่จะ model จะสร้างรูปของสุนัข จากการที่เรา train ด้วยรูปแมวโดยตัว model ที่จะพูดถึงการทำ unpaired image-to-image translation ก็คือ CycleGAN
CycleGAN จะเป็นเหมือนการที่ generator จะรับ feedback จาก generator อีกตัวเพื่อที่จะเอามาสร้างรูปอีก class หนึ่ง
Multi-Modal Image-to-Image Translation
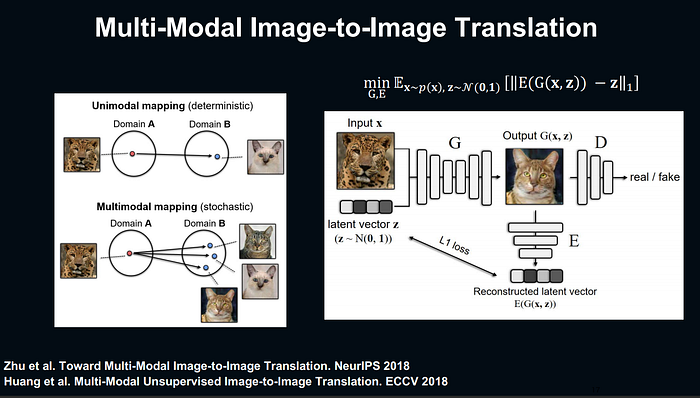
โดยรูปทางซ้ายจะเป็นการเทียบระหว่าง unimodal mapping กับmultimodel mapping โดยการทำmultimodel mapping เป็นการแก้ปัญหาของ unimodal mapping โดยเป็นการที่เราใส่ภาพเข้าไปเพียง 1 ภาพ เช่น อย่างในตัวอย่างจะเป็นการใส่รูปเสือดาว แล้วจะสร้างรูปแมวออกมาได้หลายรูป
ส่วนรูปทางด้านขวาจะอธิบายถึงโครงสร้างของตัว model โดยที่ input นอกกจากจะมีinput เป็นรูปภาพแล้วยังมีในส่วนของ latent vector เพิ่มเข้ามา โดยตัวของ latent vector จะเรียกว่า noise ก็ได้ โดยได้ latent vector มาจากการ sampling จาก gaussian distribution

หรือจะเป็นการเปลี่ยนฤดูของรูปภาพจาก ฤดูหนาว ไปเป็น ฤดูร้อน หรือเปลี่ยนสีกระเป๋า
Multi-Domain Image-to-Image Translation Model
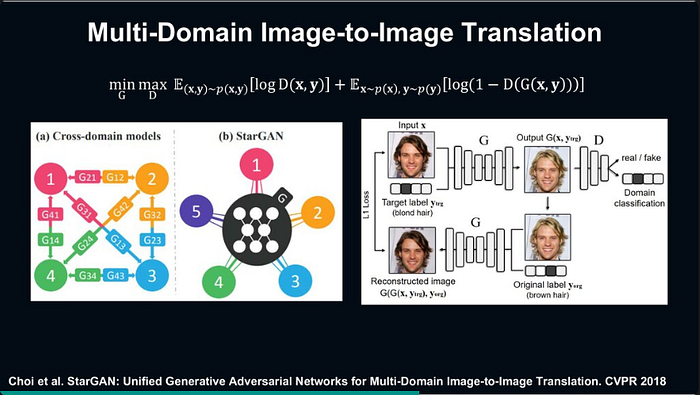
โดยจะพูดถึงตัวของ cross-domain models จะมีปัญหาถ้าเกิดมีส่วนของ target output ก็ต้องเพิ่มตัวของ generator เข้ามาเช่นกัน จึงเสนอตัวของ StarGAN เนื่องจาก StarGAN ไม่ได้รับแค่ input มาเป็นภาพ แต่ยังมีส่วนของ target label เข้าไปด้วย ทำให้ถ้าต้องการตัวของ target มากขึ้นก็เพียงแค่เพิ่ม dimension ของ label เพิ่มเข้าไป ทำให้ตัวของ generator เดียวสามารถเรียนรู้ได้หลายๆ target เช่นภาพด้านล่าง

Limitation of prior work
จากก่อนหน้านี้ จะมีข้อจำกัดจากที่ต้องทำหลายๆlabelเพื่อที่จะสร้างรูปภาพ หรือสร้างรูปภาพจาก input เดียวเป็นได้แค่อันเดียว เช่นถ้าต้องการจะสร้างรูปภาพที่ยิ้มก็จะสามารถทำได้แค่รูปยิ้มเท่านั้น ทำให้พัฒนามาเป็นตัว StarGANv2 ซึ่งคือ Multi-Domain & Multi-Modal Image-to-Image Translation
Multi-Domain & Multi-Modal Image-to-Image Translation : StarGANv2

ในส่วนของ StarGANv2 จะมาช่วยในการแก้ปัญหาจากข้างบนได้ โดยจากรูปตัวอย่าง จะสามารถสร้างรูปออกกมาเป็นสิงโตได้หลายๆแบบทั้งแบบแมวและแบบเสือ โดยส่วนของ model ของ ตัวStarGANv2 จะมีการใช้ mapping network เพื่อทำหา style code ออกมาจาก latent code จากนั้น generator จะทำการเรียนรู้เพื่อสร้าง output โดยการ reflect style code ลงไปใน input ที่เป็นภาพ โดยเมื่อทำการ generator รูปภาพออกมาแล้วจะส่งไปให้ส่วนของ encoder learn เพื่อ reconstruct style code แล้วสุดท้ายก็จะเป็นส่วนของ discriminator เพื่อใช้ในการตอบว่าแต่ละรูปทีgeneratorสร้างออกมาเป็น ภาพจริง หรือ ภาพปลอม

Multi-Domain & Multi-Modal Image-to-Image Translation : COCO-FUNIT
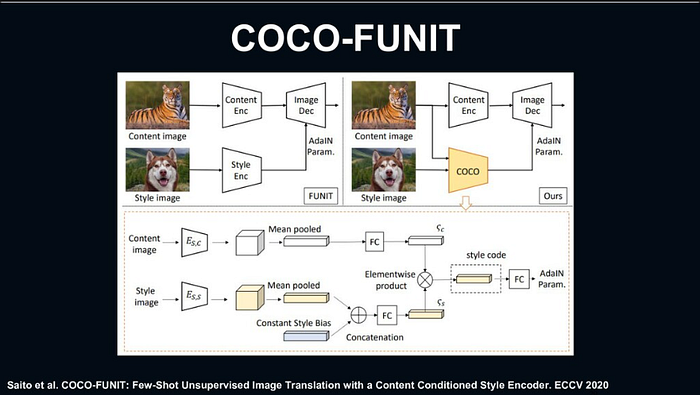
โดยจะมีการเปรียบเทียบกันของ 2 model เป็นตัวของ FUNIT กับ COCO-FUNIT โดย 2 models นี้จะต่างกันตรงที่ COCO-FUNIT จะรับ input ทั้ง content กับ style image เข้าไปที่ style encoder

โดยจากรูปด้านบน จะเป็นการเทียบระหว่าง FUNIT กับ COCO-FUNIT เพื่อให้เห็นความแตกต่าง โดยเมื่อใส่input ของ styleกับcontent เข้าไป FUNITจะมีการผสมของตัว input เข้าไปในจุดสีแดง ส่วนในตัวของ COCO-FUNIT สามารถสร้างออกรูปภาพออกมาได้
More Applications:
vid2vid

เป็นการนำ pose information ที่ได้มาจาก dancing video มารวมเข้ากับภาพที่เป็นinput เพื่อมาสร้างวิดีโอใหม่การเต้นของคนๆนั้น แม้ว่าคนๆนั้นจะไม่เคยเต้นเลยก็ตาม
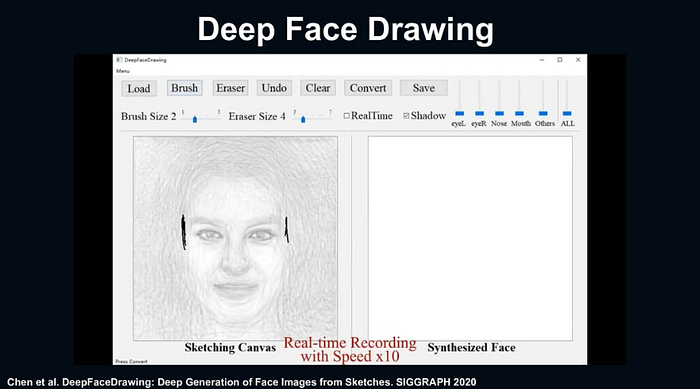
Deep Face Drawing
เป็นการสร้างรูปภาพหน้าคนจริงๆขึ้นมาจากรูปภาพสเกตซ์ แม้ว่าเราจะวาดรูปไม่เก่ง model ก็ยังสามารถสร้างรูปหน้าคนออกมาได้
เนื้อหาทั้งหมดในบทความนี้เป็นเพียง Sessions หนึ่งที่เกิดจากความสนใจส่วนตัวของผมเองจากงาน Line Developer Day 2020 เท่านั้น หากผู้ใดที่มีความสนใจในด้านอื่นๆก็สามารถที่จะเข้าไปชมย้อนหลังได้ที่ https://linedevday.linecorp.com/2020/en/sessions/8573
ขอบคุณครับ 😺